Abstract
Human Mesh Recovery (HMR) aims to reconstruct 3D human pose and shape from 2D observations and is fundamental to human-centric understanding in real-world scenarios. While recent image-based HMR methods such as SAM 3D Body achieve strong robustness on in-the-wild images, they rely on per-frame inference when applied to videos, leading to temporal inconsistency and degraded performance under occlusions. We address these issues without extra training by leveraging the inherent human continuity in videos.
We propose SAM-Body4D, a training-free framework for temporally consistent and occlusion-robust HMR from videos. We first generate identity-consistent masklets using a promptable video segmentation model, then refine them with an Occlusion-Aware module to recover missing regions. The refined masklets guide SAM 3D Body to produce consistent full-body mesh trajectories, while a padding-based parallel strategy enables efficient multi-human inference. Experimental results demonstrate that SAM-Body4D achieves improved temporal stability and robustness in challenging in-the-wild videos, without any retraining.
Method
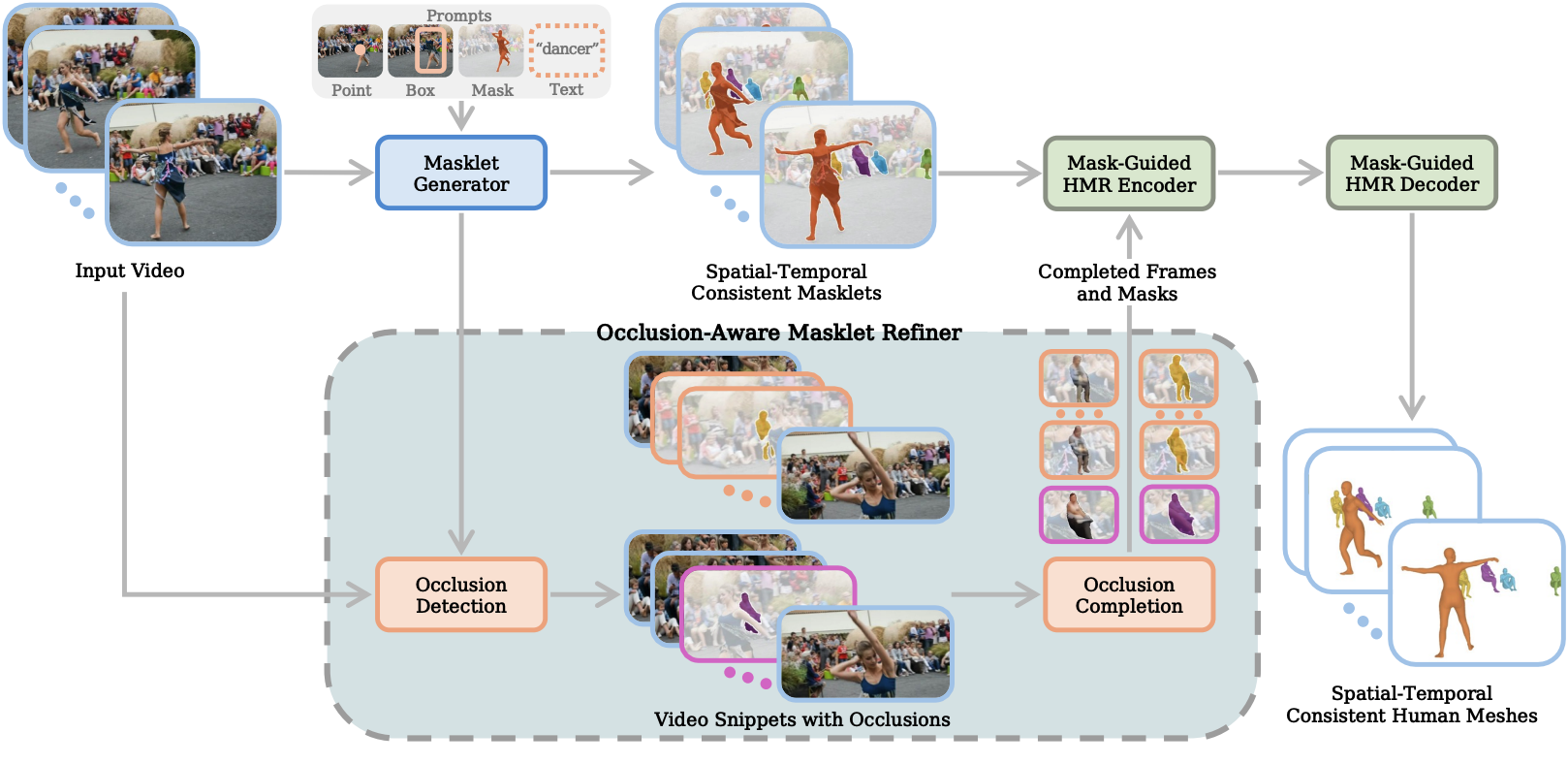
Given an input video with human prompts, SAM-Body4D operates on three main modules in a training-free manner. The Masklet Generator derives identity-consistent temporal masklets from the video to provide spatio-temporal tracking cues. The Occlusion-Aware Masklet Refiner enriches these masklets by recovering invisible body regions and stabilizing temporal alignment. Finally, the Mask-Guided HMR module uses refined masklets as spatial prompts to predict accurate and temporally coherent human meshes across the entire sequence.